Transformers: The Architecture Behind Today's AI Boom
In my last post, we pulled back the curtain on how Large Language Models (LLMs) convert text into numbers and use probability to predict the next token. I wrapped up that piece by pointing out that the current AI explosion isn’t driven by entirely new math, but rather by three specific ingredients: massive data, cheap compute, and a game-changing architecture called the Transformer.
If modern LLMs are the blockbuster hits defining the current tech landscape, the Transformer is undoubtedly the main character.
Before the Transformer arrived, AI’s ability to handle human language was hitting a massive engineering wall. Let’s look at why this architecture changed everything, how it handles data internally without getting lost in academic jargon, and how we went from a single 2017 research paper to the massive models we use every single day.
Deconstructing GPT
We hear the term “GPT” everywhere now, but before going deeper, it’s worth stripping away the marketing layer and understanding what the acronym actually means:
- Generative: At its core, the model is built to generate new data. Given a sequence of text, its sole job is to output a probability distribution for what comes next.
- Pre-trained: Before a model can act as a helpful coding assistant or chatbot, it goes through a massive unsupervised learning phase on a mountain of raw internet data. It learns the foundational syntax, patterns, and structure of human knowledge before any human fine-tunes it for specific tasks.
- Transformer: This is the underlying neural network architecture. It’s the engine that makes the “Generative” and “Pre-trained” parts scale so incredibly well.
The Origin Story: Attention Is All You Need
In 2017, a team of researchers at Google published a paper with a beautifully confident title: “Attention Is All You Need.” They weren’t trying to invent a sci-fi artificial consciousness; they were simply trying to improve language translation software.
To understand why their solution was a breakthrough, you have to look at what we were using before. The old gold standards for processing text sequences were Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs).
RNNs process data exactly like a human reads: word by word, from left to right. If you feed an RNN a long paragraph, it processes the first word, updates its internal memory state, carries that memory to the second word, and repeats.
This approach brought two massive engineering headaches:
- The Fragile Memory Problem: As the sentence grows longer, the early words get progressively diluted. By the time an RNN reaches word 500, the context of word 3 has effectively vanished from its short-term memory.
- The Sequential Bottleneck: Because word N depends entirely on the memory state of word N−1, you cannot compute them at the same time. This was a massive waste of modern hardware. GPUs are built to crunch giant piles of matrix mathematics in parallel, but RNNs forced them to sit and wait in a single-file line.
The Transformer paper threw out recurrence entirely. Instead of moving through text step-by-step, it looks at the entire sequence of text all at once.
How It Works Internally (The High-Level Data Flow)
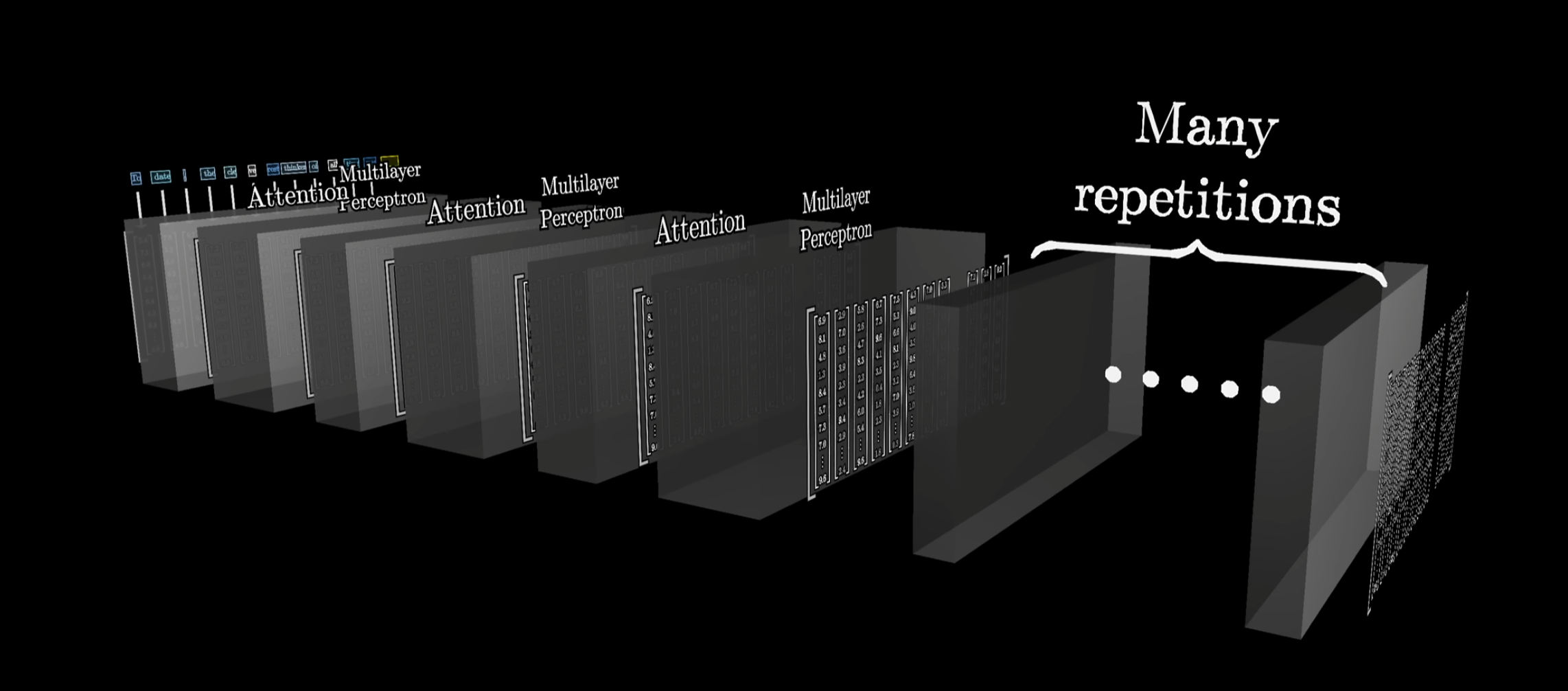
When you pass text into a Transformer, the internal data pipeline looks like a highly optimized assembly line:
1. Tokens to High-Dimensional Vectors
As we established last time, text is broken down into tokens (numbers). The Transformer looks up these tokens in a massive Embedding Matrix. This turns each token into a vector in a high-dimensional space (for instance, GPT-3 uses 12,288 dimensions). In this space, directions carry semantic meaning-words with similar vibes or grammatical roles sit closer together.
2. The Self-Attention Block
Once the entire sequence is converted into vectors, they pass into the heart of the machine: the attention mechanism. Instead of relying on a fragile carried memory, tokens are allowed to “talk” to each other dynamically.
To make this happen, every single vector creates three smaller vectors using specialized weight matrices:
- Query (Q): Think of this as a token asking: “Here is what I am looking for.”
- Key (K): Think of this as a token responding: “Here is what I contain.”
- Value (V): This is the actual information the token passes along if a Query matches its Key.
The model calculates the dot product of the Queries and Keys across all tokens to build an Attention Pattern a giant grid scoring exactly how much every word should care about every other word in the prompt.
This is how the model handles context beautifully. If the model sees the word “mole,” the attention mechanism looks across the sequence. If it spots terms like “biopsy” or “skin,” the attention pattern updates the vector for “mole” to point toward a medical definition. If it spots “carbon dioxide,” the vector is pulled toward chemistry.
3. Parallel Processing (MLPs)
Once the attention weights are settled, the vectors ingest their respective Value updates. They are then run in parallel through a feed-forward layer (a Multi-Layer Perceptron).
This entire sequence-attention talking, followed by parallel math updates and repeats across dozens of stacked layers. By the time the data reaches the final layer, the original, context-free vector has soaked up a hyper-nuanced meaning of the entire prompt.
Transformer Facts
- It’s Just Massive Matrix Multiplication: Strip away the hype, and almost all of the actual computation inside a model like ChatGPT is just giant piles of Matrix-Vector products. For example, in GPT-3, its famous 175 billion weights are organized into roughly 28,000 distinct matrices, but they all boil down to just 8 functional categories of operations.
- Bigger Models Are Mostly the Same Recipe, Bigger: GPT-1 → GPT-2 → GPT-3 did not require inventing a new kind of machine each time. Same core idea (Transformer + predict next token), more weights and more data. A lot of the “AI revolution” is scale and engineering, not a new trick every year.
From a 2017 Paper to GPT-3: The Scaling Experiments
Once Google proved the Transformer architecture worked for translation, OpenAI realized it could be used for something much bigger: scaling up text generation across the entire internet.
- GPT-1 (2018): OpenAI proved that stacking Transformers and forcing them to play the “predict the next token” game on unlabelled data allowed the model to naturally learn syntax, grammar, and basic facts without explicit supervision.
- GPT-2 (2019): They scaled the architecture up to 1.5 billion parameters. The model began displaying “zero-shot” capabilities-meaning it could solve tasks it wasn’t specifically trained to do, simply by predicting patterns. The stories it generated were starting to look coherent, though they still occasionally went off the rails.
- GPT-3 (2020): This was the massive paradigm shift. Without modifying the fundamental math introduced in the 2017 Transformer paper, OpenAI scaled the network to 175 billion parameters. At this size, quantity became quality. The sheer scale unlocked emergent properties: coherent long-form writing, basic reasoning simulation, and the ability to write executable code.
The Foundation of Modern AI
The real victory of the Transformer isn’t just that it performs advanced autocomplete incredibly well. It’s that it provided the entire tech industry with a universal architecture.
By formatting everything as token vectors and throwing out specialized sequential loops, the exact same underlying mechanism can process text, source code, image pixels, and audio waves. It turned the problem of AI development from a puzzle of complex linguistic programming into a pure engineering challenge of parallel computing scale.
Want to see the math in action?
If you need to see how data flows to truly understand it, these videos by 3Blue1Brown are worth watching. They show exactly how these vectors shift, how the attention grid is calculated, and how the matrices work under the hood: